Numpy, 리스트, 딕셔너리, DataFrame 상호 변환하기
데이터 프레임은 파이썬의 리스트, 딕셔너리, 넘파이의 ndarry (배열) 과 상호로 변환할 수 있습니다.
앞으로 우리가 사용할 사이킷런 이라는 기계학습 라이브러리 사용에 있어서 API가 DataFrame 을 인자로 입력받을 수 있지만, 기본적으로 넘파이 ndarray 를 사용하는 경우가 대부분 입니다.
그렇기 때문에 데이터 프레임과 넘파이 ndarray 의 상호 변환은 자주 발생하므로 숙지해둡시다.
넘파이 ndarray 와 리스트와 달리 데이터 프레임은 칼럼명을 가지고 있습니다.
변환 시에 칼럼명을 지정하지 않으면 자동으로 칼럼명을 할당합니다.
또한 데이터 프레임은 행과 열을 가지는 2차원 데이터이므로 2차원 이하만 데이터 프레임으로 변환될 수 있습니다.
(1) 리스트와 배열 -> 데이터 프레임 변환
우선 리스트를 생성한 뒤, 리스트를 넘파일 배열로 변환하고
각각의 리스트와 넘파일 배열을 데이터 프레임으로 만들어보겠습니다.
1차원 데이터 프레임을 만들 것이라 칼럼 필드 명은 하나만 만들게요.
import numpy as np
col_name=['필드명']
list = [1, 2, 3] # 리스트 생성
array = np.array(list) # 생성된 리스트로 넘파이 배열 생성
print('변환된 넘파이 배열 : \n', array)
print("")
df_list = pd.DataFrame(list, columns=col_name)
print('리스트로 만든 데이터 프레임: \n\n' ,df_list)
print("")
df_array = pd.DataFrame(array, columns=col_name)
print('배열로 만든 데이터 프레임: \n\n',df_array)

이번에는 2행 3열 형태의 2차원 형태의 데이터를 만들어보겠습니다.
col_name2=['첫째', '둘째', '셋째']
list2 = [
[1, 2, 3],
[4, 5, 6]
]
array2 = np.array(list2)
print('변환된 2행 3열의 넘파이 배열 : \n\n', array2)
print('\n',array2.shape)
print("")
df_list2 = pd.DataFrame(list2, columns=col_name2)
print('두 번째 리스트로 만든 데이터 프레임: \n\n' ,df_list2)
print("")
df_array2 = pd.DataFrame(array2, columns=col_name2)
print('두 번째 배열로 만든 데이터 프레임: \n\n',df_array2)

(2) 딕셔너리 -> 데이터 프레임 변환
이번에는 딕셔너리를 변환해봅니다.
딕셔너리의 Key 키는 칼럼명으로 딕셔너리의 Value 값은 키에 해당하는 칼럼 데이터로 변환됩니다.
그러므로 키의 경우 문자열, 값의 경우 리스트 또는 배열의 형태로 딕셔너리를 구성하는 것이 대부분 입니다.
dict = {
'첫 번째 행':[1, 2],
'두 번째 행':[3, 4],
'세 번째 행':[5, 6]
}
df_dict = pd.DataFrame(dict)
print('딕셔너리로 만든 데이터 프레임 : \n\n', df_dict)

key 값은 칼럼명으로, value 값은 칼럼 데이터로 매핑 되었습니다.
(3) 데이터 프레임 -> 배열, 리스트, 딕셔너리로 변환
머신러닝 패키지의 입력 인자 등에 적용하기 위해 데이터 프레임을 넘파이 ndarray 로 배열로 변환하는 경우가 많습니다.
데이터 프레임 -> ndarray 배열 로 변환하는 것은 values 를 이용해서 쉽게 할 수 있습니다.
values는 매우 많이 사용되기 때문에 꼭 기억해둡시다!
위에서 생성한 딕셔너리 -> 데이터 프레임 변환자료를 다시 -> ndarray 배열로 변환해보겠습니다.
array3 = df_dict.values
print(array3)

데이터프레임 -> 리스트 로 변환하는 것은 values 로 얻은 ndarray 에서 tolist() 를 호출하면 됩니다.
데이터프레임 -> 딕셔너리로 변환하는 것은 DataFrame 객체의 to_dict() 메소드를 호출하면 되는데, 인자로 list를 입력하면 딕셔너리의 값이 리스트형으로 반환됩니다.
list3 = df_dict.values.tolist() # 데이터프레임을 배열로 변환후 tolist()로 리스트 변환
print(list3)
print("")
dict3 = df_dict.to_dict('list')
print(dict3)
print("")
dict3 = df_dict.to_dict()
print(dict3)

데이터 프레임과 배열의 변환은 앞으로도 자주 쓸 예정이니 꼭 여기에서 익숙해지고 갑니다 ^^
데이터 프레임의 칼럼 데이터 세트 생성, 수정
DataFrame 의 칼럼 데이터와 생성, 수정은 [ ] 연산자 내에 새로운 칼럼명을 입력하고 값을 할당해주면 됩니다.
titanic_df['새롭게생성된컬럼'] = 0
titanic_df['짠!생성'] = 0
titanic_df.head(3)

오른쪽에 새롭게 생성된 컬럼들을 볼 수 있습니다.
그 아래의 값들은 새로 할당한 값인 '0' 으로 모든 데이터 세트에 일괄적으로 적용됩니다.
이번에는 기존 칼럼 시리즈의 데이터를 통해 새로운 칼럼 시리즈를 만들겠습니다.
titanic_df['나이 한 살 더 '] = titanic_df['Age']+1 + titanic_df['짠!생성']+1
titanic_df.head(3)
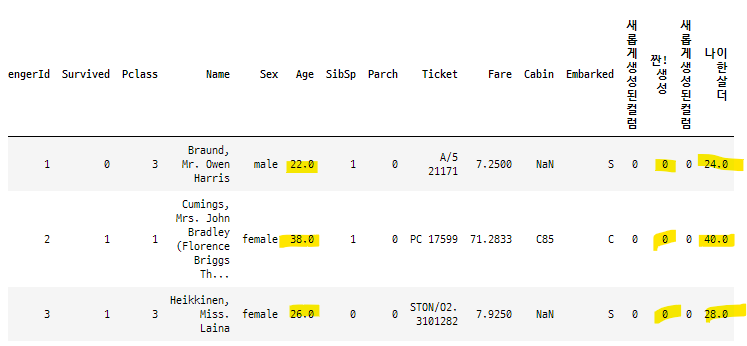
승객들의 나이 행렬에서 1 살을 추가하고, 짠!생성 행렬에서 1을 추가한 값을 더해 새로운 컬럼을 만듭니다.
총 +2 가 더해진 값이 나이 한살 더 행렬에 추가되었어요.
이렇게 기존 칼럼의 시리즈를 가공해서 새로운 칼럼 시리즈를 만들 수 있습니다.
또한 기존 칼럼의 시리즈 값을 쉽게 일괄적으로 수정하여 업데이트 할 수도 있습니다.
titanic_df['짠!생성'] = titanic_df['짠!생성'] + 500
titanic_df.head(3)

drop() 데이터 프레임의 데이터 삭제
DataFrame 의 데이터 삭제는 drop() 메소드를 이용합니다.
drop() 메소드는 다음과 같은 원형을 갖습니다.
dataframe.drop(labels, axis, index, columns, level, inplace, errors)
이 중 디폴트 값은 labels = None, axis = 0, index = None, columns = None, level = None, inplace = False, erros= 'raise' 입니다.
- label : 삭제할 레이블 명 입니다. axis 를 지정해주어야 함
- axis : 0은 로우 방향 축(index 값) 1은 칼럼 방향 축(columns 값) 을 의미
- index : 인덱스명을 입력하여 바로 삭제할 수 있음
- columns : 컬럼명을 입력하여 바로 삭제할 수 있음
- level : 멀티인덱스의 경우 레벨을 지정해서 진행할 수 있음
- inplace : 원본을 변경할지 여부를 결정하며 True 의 경우 원본이 변경됨
- errors : 삭제할 레이블을 찾지 못할 경우 오류를 띄울지 여부. ignore 할 경우에는 존재하는 레이블만 삭제. raise는 예외를 발생시킴.
이 중 가장 중요한 파라미터는 labels, axis, inplace 입니다.
axis 는 기존에 인덱싱을 공부하며 확인한 적이 있습니다.
https://blue-dot.tistory.com/177
파이썬 머신러닝 입문 공부일지 2. Numpy 기본 함수 공부 (2) 넘파이 배열 인덱싱, 슬라이싱, 정렬과
앞서 Numpy 넘파이의 기본 배열 함수에 대해서 알아보았습니다. 이번에는 선택자 함수인 인덱싱과 슬라이싱 그리고 정렬에 대한 것을 알아보겠습니다. Numpy의 선택함수 인덱싱, 슬라이싱 ndarray 인
blue-dot.tistory.com
drop() 메소드에 axis = 1 을 입력하면 칼럼 축 방향으로 드롭을 수행하고 axis = 0 의 경우 로우 축 방향으로 드롭을 수행합니다.
저는 처음에 칼럼 축 방향 이라는 것이 매우 혼란했는데요..
axis = 1 일 경우 '지정된 칼럼(열)을 드롭한다' axis= 0 일 경우 '지정된 로우(행)을 드롭한다' 로 이해하시면 좋을 것 같습니다.
칼럼 축 방향이라는 것은 칼럼 축에 있는 하나의 칼럼을 삭제하는 것으로
labels 에 값을 입력하면 그 특정 값을 인덱스로 인식하여 해당하는 칼럼을 삭제합니다.
여러개의 칼럼을 삭제하고 싶으면 리스트 형태로 삭제하고자 하는 칼럼명을 입력해 labels 파라미터에 입력하면 됩니다.
(ex. drop_result = titanic_df.drop(['Age', 'Sex', 'Ticket'], axis=1)

drop() 메소드가 사용되는 것은 특정 칼럼을 드롭하는 경우가 대부분입니다.
기존 칼럼을 가공해서 새로운 칼럼을 만들고 삭제하는 경우가 많아서 axis= 1 을 설정하고 드롭하는 경우가 많습니다.
axis = 0 으로 해당 로우 값을 삭제하는 경우는 이상치 데이터를 삭제하는 경우가 대부분 입니다.
그럼 앞선 예제를 통해 다시 한 번 확인해볼게요.
저는 아까 '새롭게 생성된 컬럼'이 두 개가 생겼던 것이 별로 예쁘지 않아서 해당 컬럼을 삭제하고 시작하겠습니다.
titanic_df = titanic_df.drop('새롭게생성된컬럼', axis=1)
titanic_df = titanic_df.drop('새롭게 생성된 컬럼', axis=1)
titanic_df.head(3)

새롭게 생성된 컬럼이 있었는데요 없었습니다.
이번에는 앞서 중요하다고 말씀드렸던 inplace 파라미터에 대해서 알아볼게요.
이 포스트를 작성하는 것은 2022년에 시작했지만, 완성시키는 것은 2023년 1월 3일 이므로
한 살 더 나이 먹는 것는 건 서글프니 나이 한 살 더 칼럼을 삭제해볼까요.
이번에는 새로운 데이터 프레임인 titanic_drop_df 로 별칭하여 만들어보겠습니다.
titanic_drop_df = titanic_df.drop('나이 한 살 더 ', axis=1)
titanic_drop_df.head(3)

한 살 더 먹은 칼럼이 사라졌습니다.
그런데 titanic_df 의 원본을 확인해보니...
titanic_df.head(3)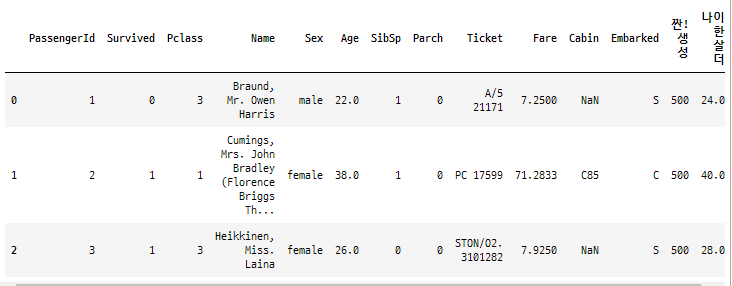
나이는 변함없이 한 살 더 먹었습니다. ^^
이것은 앞의 예제에서 inplace=False 로 되어 있는 디폴트 값을 사용해서 그렇습니다.
inplace=Flase 이면 원본의 데이터 프레임은 삭제되지 않으며 삭제된 결과의 데이터 프레임만을 반환합니다.
inplace =True 로 설정하면 자신의 데이터 프레임에서 데이터를 삭제합니다.
여기까지 내용들을 한 번 정리하고 지나갈게요.
- axis : DataFrame 의 로우(행)을 삭제할 때에는 axis = 0, 칼럼(열)을 삭제할 때에는 axis = 1
- 원본 DataFrame 은 유지하고 드롭된 DataFrame을 새롭게 객체 변수로 받고 싶다면 inplace = False 로 설정
- 원본 DataFrame 에 드롭된 결과를 적용하고 싶을 때에는 inplace = True 적용
'AI 머신러닝 딥러닝 > 파이썬 머신러닝 입문 공부일지' 카테고리의 다른 글
| 파이썬 머신러닝 입문 공부일지 5. Pandas 판다스 Index 객체 (1) | 2023.01.03 |
|---|---|
| 파이썬 머신러닝 입문 공부일지. 회귀 분석의 회귀란 무슨 뜻일까? (0) | 2023.01.02 |
| 파이썬 머신러닝 입문 공부일지 3. 판다스 Pandas, DataFrame 관련 메소드 기능들 (1) (0) | 2022.12.27 |
| 파이썬 머신러닝 입문 공부일지 2. Numpy 기본 함수 공부 (2) 넘파이 배열 인덱싱, 슬라이싱, 정렬과 선형대수 연산 (0) | 2022.12.23 |
| 파이썬 머신러닝 입문 공부일지 1. 머싱러닝의 시작 / Numpy 기본 함수 공부 (1) (0) | 2022.12.23 |