오늘부터는 파이썬 머신러닝에 대한 공부를 시작합니다!
공부에 참고하는 책은 다음과 같습니다.
파이썬 머신러닝 완벽 가이드 - YES24
『파이썬 머신러닝 완벽 가이드』는 이론 위주의 머신러닝 책에서 탈피해 다양한 실전 예제를 직접 구현해 보면서 머신러닝을 체득할 수 있도록 만들었다. 캐글과 UCI 머신러닝 리포지토리에서
www.yes24.com
저자의 소스 코드 참고 깃허브 : https://github.com/wikibook/ml-definitive-guide
GitHub - wikibook/ml-definitive-guide: 《파이썬 머신러닝 완벽 가이드》 예제 코드
《파이썬 머신러닝 완벽 가이드》 예제 코드. Contribute to wikibook/ml-definitive-guide development by creating an account on GitHub.
github.com
머신러닝, 딥러닝과 어디서든 시시각각 들을 수 있는 단어들이지요.
어디서든 이것이 제4차 산업계에서 무척 중요한 역할을 한다고 합니다.
그럼 머신러닝이 대체 어떤 것인지 개념부터 같이 알아볼게요.
머신러닝이란?
머신러닝이란 어플리케이션을 수정하지 않고도 데이터를 기반으로 패턴을 학습하고 결과를 예측하는 알고리즘 기법의 통칭입니다.
가령 우리가 도박과 관련된 스팸메일을 걸러내기 위한 앱을 개발한다고 했을 때
우리가 하나씩 '바1카라', '홀0덤' 과 같은 스팸 단어들을 기입을 할 수 있지만, 이것을 하나씩 직접 하다보면 너무 번거로운 작업이 되겠죠. 머신러닝은 이러한 작업을 알고리즘을 통해 반복하고 실행합니다.
즉, 우리가 앱 안에 데이터들을 계속 누적해서 넣어두면 어떤 것이 도박과 관련된 내용인지에 대한 패턴이 쌓이기 시작합니다.
그럼 알고리즘을 통해 어떤 것이 스팸인지 그 패턴을 분석하는 것이에요.
그렇기 때문에 우리는 머신러닝을 기계학습이라는 말로도 부릅니다.
머신 -> 기계가
러닝 -> (패턴을) 배운다 학습한다.
머신러닝은 그 데이터를 기반으로 숨겨진 패턴을 인식하고, 데이터를 기반으로 통계적인 신뢰도를 만듭니다.
예측 오류를 최소화하기 위해서 머신러닝 기반의 예측 분석을 통해 스팸 메일을 걸러내는 앱의 질을 높입니다.
머신러닝의 두 축이라고 하는 것은 데이터와 알고리즘입니다.
머신러닝의 특징
- 데이터에 매우 의존적입니다.
이런 말이 있어요. Garbage in, Garbage out. 쓰레기를 넣으면 쓰레기가 나온다.
좋은 품질의 데이터를 갖추지 못한다면 머신러닝의 수행결과도 좋을 수 없습니다.
- 학습 데이터 기반의 로직은 현실에서는 좋지 않을 수 있습니다.
가령 90%의 아웃풋이 나왔던 로직이 실제에서는 70%의 아웃풋이 나올 수도 있습니다.
이것을 과적합이라고 합니다.
- 머신러닝에 주로 쓰이는 언어는 파이썬과 R입니다.
R은 통계 전용 프로그래밍 언어입니다.
개발 언어에 익숙하지 않지만, 통계 분석을 빠르게 하고 싶다면 R이 적합할 수 있습니다.
그러나 개발 언어에 익숙하고, 이제 막 머신러닝을 시작하려고 하는 사람이라면 Python 이 더 적합할 수 있습니다.
Numpy
머신러닝의 주요 알고리즘은 선형대수와 통계 등에 기반합니다.
numpy 는 선형 대수 관련 기능을 포함해 다양한 연산기능을 제공합니다.
또한 C/C++ 과 같은 저수준 언어 기반의 호환 API를 제공합니다.
(저수준이라는 것은 저급하다는 것이 아니라 하드웨어 수준에 가까운 언어라는 뜻입니다! 수준은 level 이라고 합니다. low level language 언어일 수록 프로그램 난이도가 높습니다. Python 은 high level language 입니다.)
따라서 기존 프로그램과 데이터를 주고 받거나 API를 호출해 쉽게 통합할 수 있게 해줍니다.
넘파이Numpy 는 배열 기반의 연산은 물론이고 다양한 데이터 핸들링 기능을 제공합니다.
그러나 비슷한 역할을 수행하는 판다스Pandas 의 함수들이 보다 직관적이어서 판다스Pandas로 대체하는 경우가 대부분입니다.
Numpy에서 배열을 주고, 배열의 멤버들이 2행 2열 (데이터값 4개) 일 경우.
데이터를 바꾸거나 데이터의 제목을 바꾸는 것을 Numpy로도 할 수 있지만, Pandas 로 작성하는 것이 보다 직관적(보기 좋고 편한) 이기 때문에 대부분 Pandas로 합니다.
Numpy 예제
ndarray, ndim
1차원, 2차원, 3차원... 이런 말을 들어보셨을 것입니다.
이것은 점, 선, 면, 입체로 구성된 각 도형들을 분류하는 것입니다.
라인의 수가 n차원을 정합니다.
이렇게 점 하나는 0 차원, 직선이 되는 순간 1차원으로 차원의 수가 시작됩니다.

Numpy의 ndarray 는 배열로 차원을 만드는 함수입니다.
import numpy as np
#멤버가 될 값을 전달하여 배열을 생성합니다.
array1 = np.array([1, 2, 3])
print("array1 타입 : ", type(array1))
print("array1 형태(행열) : ", array1.shape)
# Numpy ndarray
array2 = np.array([[1, 2, 3], [2, 3, 4]])
print("array2 타입 : ", type(array2))
print("array2 형태(행열) : ", array2.shape)
Nympy의 ndim 함수는 몇 차원의 배열인지를 출력해줍니다.
# Numpy ndarray
import numpy as np
#멤버가 될 값을 전달하여 배열을 생성합니다.
array1 = np.array([1, 2, 3])
print("array1 타입 : ", type(array1))
print("array1 형태(행열) : ", array1.shape)
# Numpy ndarray
array2 = np.array([[1, 2, 3], [2, 3, 4]])
print("array2 타입 : ", type(array2))
print("array2 형태(행열) : ", array2.shape)
#ndim 몇 차원인지 출력해준다.
#멤버 변수 사용하면 몇 차원인지가 반환이 된다.
print(f"array1 배열은 {array1.ndim}차원이고, array2 배열은 {array2.ndim}차원이다.")
Numpy 배열의 데이터 타입
ndarray, dtype, astype
ndarray (배열 생성 함수) 가 포함할 수 있는 데이터 타입은 다음과 같습니다.
- 숫자형 int
- 숫자형 unsigned int : sign은 부호를 뜻하며, 양수와 0만 존재하는 숫자형 정수
- 숫자형 float
- 숫자형 complex : 크거나 정밀한 값을 위한 것.
- 문자열
- 불리언
Numpy 배열 내 데이터 타입은 연산 특성상 같은 타입만 가능합니다.
배열 내 데이터 타입은 dtype 멤버 변수로 확인할 수 있습니다.
list1 = [1, 2, 3]
print(type(list1))
array1 = np.array(list1)
print(type(array1))
print(array1, array1.dtype)
#정수는 int8, int16, int32 등으로 표현할 수 있다.
만약 자료형이 섞인 리스트를 Numpy 배열로 변환하게 되면, 자동 형 변환이 일어나게 됩니다.
이 내용은 예전 python 에서도 서술한 바 있으니 해당 내용도 같이 첨부합니다.
https://blue-dot.tistory.com/41
자바 기초 공부 일지 5. 상수 (리터럴), 자료형 변환
● 변수에 값을 딱 한 번 할당할 수 있으면 상수입니다. 한 번 할당된 값은 변경이 불가능하며 키워드 final 이 붙어있는 변수를 상수라고 합니다. ex) final in MAX_SIZE = 100; (초기화 하지 않으면 딱 한
blue-dot.tistory.com
다음 코드를 보며 확인해봅니다.
list1 = [1, 2, 3]
print(type(list1))
array1 = np.array(list1)
print(type(array1))
print(array1, array1.dtype)
#정수는 int8, int16, int32 등으로 표현할 수 있다.
list2 = [1, 2, 'test']
array2 = np.array(list2)
print(array2, array2.dtype)
list3 = [1, 2, 3.0]
array3 = np.array(list3)
print(array3, array3.dtype)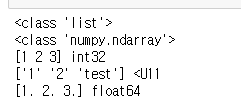
<class 'list'>
<class 'numpy.ndarray'>
[1 2 3] int32 # 정수는 int8, int16, int 32 로 명시될 수 있습니다.
## 8비트(1바이트) 크기의 부호 있는 정수형, 16비트(2바이트) 크기의 부호 있는 정수형, 32비트(3바이트) 크기의 부호 있는 정수형을 말합니다.
['1' '2' 'test'] <U11 # 문자열이라는 type 명시
[1. 2. 3.] float64 # 실수형이라는 type 명시
astype 메소드를 이용하면 타입 변경이 가능합니다.
이는 메모리를 절약해야하는 상황에 주로 사용됩니다.
단, 메모리 손실이 프로그램에 어떤 영향을 끼칠지 고려할 필요는 있습니다.
파이썬으 실행속도 자체를 고려해야 합니다.
array_int = np.array([1, 2, 3])
array_float = array_int.astype("float64")
print(array_float, array_float.dtype)
array_int = array_float.astype("int32")
print(array_int, array_int.dtype)
ndarray 의 자동생성 함수
다음으로는 ndarray 를 편리하게 생성하는 것을 확인해보겠습니다.
자동생성과 연관된 함수입니다.
- arange() : 범위를 정해 배열을 생성하기
- zero() : 0으로 채워진 배열을 생성하기
- ones() : 1로 채워진 배열을 생성하기
sequence_array = np.arange(10)
print(sequence_array)
print("\n")
sequence_array = sequence_array.reshape(2, 5) # 2행 5열로 재배열
print(sequence_array)
print("\n")
zero_array = np.zeros((2, 3)) # shape을 지정해서 생성할 수 있다.
print(zero_array)
print("\n")
ones_array = np.ones((2, 3)) # shape을 지정해서 생성할 수 있다.
print(ones_array)
여기까지 머신러닝의 학습을 위한 기본 베이스 공부 중
기본 개념과 Numpy 기본 함수들에 대해서 알아보았습니다.
다음에는 다른 함수들도 같이 확인해볼게요!
'AI 머신러닝 딥러닝 > 파이썬 머신러닝 입문 공부일지' 카테고리의 다른 글
| 파이썬 머신러닝 입문 공부일지 5. Pandas 판다스 Index 객체 (1) | 2023.01.03 |
|---|---|
| 파이썬 머신러닝 입문 공부일지. 회귀 분석의 회귀란 무슨 뜻일까? (0) | 2023.01.02 |
| 파이썬 머신러닝 입문 공부일지 4. 판다스 Pandas, DataFrame 관련 메소드 기능들 (2) (0) | 2022.12.27 |
| 파이썬 머신러닝 입문 공부일지 3. 판다스 Pandas, DataFrame 관련 메소드 기능들 (1) (0) | 2022.12.27 |
| 파이썬 머신러닝 입문 공부일지 2. Numpy 기본 함수 공부 (2) 넘파이 배열 인덱싱, 슬라이싱, 정렬과 선형대수 연산 (0) | 2022.12.23 |