앞서 Numpy 넘파이의 기본 배열 함수에 대해서 알아보았습니다.
이번에는 선택자 함수인 인덱싱과 슬라이싱 그리고 정렬에 대한 것을 알아보겠습니다.
Numpy의 선택함수
인덱싱, 슬라이싱
ndarray 인덱싱
몇 번째 index 멤버에 접근한다는 인덱싱Indexing을 Numpy에서도 사용할 수 있습니다.
Numpy 배열의 indexing 의 종류는 다음과 같습니다.
- 특정 데이터만 추출 : 리스트, 튜플 등에서의 인덱싱과 동일. 숫자를 잘못 쓰면 값에 오류가 납니다.
- 슬라이싱Slicing : 리스트, 튜플에서의 슬라이싱과 동일. 숫자를 잘못 써도 오류가 나지는 않지만 결과는 기댓값과는 달라질 수 있습니다.
- 팬시 인덱싱Fancy Indexing : 일정한 인덱싱 집합을 리스트 또는 배열 형태로 지정해 해당 위치에 있는 값 반환합니다.
- 불리언 인덱싱Boolean Indexing : 특정 조건에 해당하는지 여부를 기반으로 배열 값 반환합니다. 과거의 필터와 비슷한 역할을 하며, 조건식을 기반으로 합니다.
인덱싱과 슬라이싱에 대해서는 아래의 파이썬 공부일지에서 작성한 것이 있습니다.
https://blue-dot.tistory.com/16
파이썬 공부일지 13. 리스트!
이제 파이썬으로 본격 코딩을 조금조금씩 맛보고 있는데, 진짜 재밌네요! 무에서 유를 만드는 느낌... 정말 망망대해에서 그물 짓고 있는 기분이에요.. 다시 또 시작해봅시당. 지금까지 공부한
blue-dot.tistory.com
하나씩 예제를 보면서 확인해볼게요.
array1 = np.arange(1, 10) # 범위를 적을 수 있으며 각각 1과 10의 값은 매개변수 지정하기를 통해 사용 가능합니다.
print(array1)
print("\n")
array1 = np.arange(start=1, stop=10) # 범위를 적을 수 있으며 각각 1과 10의 값은 매개변수 지정하기를 통해 사용 가능합니다.
print("첫 번째 : ", array1)
print("두 번째 : ", array1[2])
print("세 번째 : ", array1[4:7])
print("\n")
array2 = array1.reshape(3,3)
print(array2)
print(array2[1,0]) #리스트 중첩과 달리 배열은 이렇게 합니다.
#리스트 중첩의 경우 [1] 행의 [0]열을 볼때 [1][0]으로 작성하지만
#배열은 [1,0] 1행의 0열을 볼 때 이렇게 작성합니다.
아래는 위 인덱싱을 활용해서 가벼운 예제를 풀어볼게요.
1) 인덱싱 예제
# 1부터 12로 채워진 4행 3열짜리 배열을 만들고 6을 인덱싱
array1 = np.arange(1,13)
array2 = array1.reshape(4,3)
print(array2[1,2])
#코드를 이렇게 줄일 수도 있습니다.
print(np.arange(1,13).reshape(4,3)[1,2])

2) 슬라이싱 예제
슬라이싱은 복사본을 자르는 것입니다.
배열의 원본은 그대로 유지를 하고 슬라이싱을 하는 부분만 복사를 하게 됩니다.
즉, 원본을 훼손하지 않습니다.
슬라이싱을 할 때에는 값의 생략이 가능합니다. 첫 번째 값을 생략하면 처음부터, 뒤의 값을 생략하면 끝까지 슬라이싱을 합니다. [ : ] <- 일 경우 전체 복사가 됩니다.
array1 = np.arange(10)
print(array1[2:5]) # 2부터 4까지 슬라이싱을 하고 싶다면 마지막 숫자 + 1 로 슬라이싱을 합니다.
print(array1[:])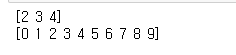
슬라이싱도 인덱싱과 똑같은 방식으로 적용할 수 있습니다.
array1 = np.arange(10)
print(array1[2:5]) # 2부터 4까지 슬라이싱을 하고 싶다면 마지막 숫자 + 1 로 슬라이싱을 합니다.
print(array1[:])
print("\n")
array1 = array1.reshape(5, 2) # 5행 2열로 변환
print(array1)
print("\n")
print(array1[0:2]) # 0행부터 2행 전까지 슬라이싱

코드의 마지막 줄에 있는 0행부터 2행 전까지의 슬라이싱을 한 배열에
다시금 슬라이싱을 할 수 있습니다.
print(array1[0:2, :1]) # 0행부터 2행 전까지 슬라이싱한 뒤에 전체 행에서 1행까지를 다시 슬라이싱

3) 팬시 인덱싱 예제
array1d = np.arange(start=1, stop=10)
array2d = array1d.reshape(3, 3)
print(array2d)
array3 = array2d[[0,1],2]
print("array3: ", array3)
array3 = array2d[[0,2],2]
print("array3: ", array3)array3 = array2d[[0,2],2]
의 경우 0과 2번째 각각의 행에서 2번 인덱스의 값을 구하는 것이므로 3과 9가 인덱스 됩니다.

4) 필터 역할을 하는 배열의 불린 인덱싱 예제
# 필터 역할을 하는 배열의 불린 인덱싱
array1 = np.arange(3, 9)
# 인덱싱 기호 [] 안에서는 배열명을 요소로 취급
array1 = array1[array1 > 5]
print(array1)
array2 = np.array([True, True, True, True, False, True, False])
array2 = array2[array2]
print(array2)
행렬의 정렬
sort() , argsort()
- np.sort() : 본래의 행렬은 유지한 채 정렬 결과를 반환합니다.
- ndarray.sort() : 본래의 행렬의 정렬 후 결과 반환은 없습니다.
import numpy as np
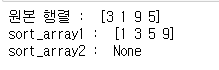
org_array = np.array([3, 1, 9, 5])
print("원본 행렬 : ", org_array)
sort_array = np.sort(org_array) # 원 행렬은 유지
print("sort_array1 : ", sort_array)
sort_array2 = org_array.sort() # 원 행렬을 정렬
print("sort_array2 : ", sort_array2)
sort_array1_desc = np.sort(org_array)[::-1]
[ ::-1 ] 는 확장된 슬라이싱입니다.
기본적으로 슬라이싱(복사) 역할을 합니다. - 음수로 되어 있다면 내림차순(역순)으로 정렬한다는 뜻을 갖습니다.
음수 대신에 양수를 쓰거나 숫자를 안 쓸 경우 오름차순(순방향)으로 정렬됩니다.
sort_array1_desc = np.sort(org_array)[::-1]
print("역순으로 정렬되는지 확인 -> ", sort_array1_desc)
axis를 활용해서 행과 열 별로 오름차순 내림차순을 정렬해보겠습니다.
array2d = np.array([8,12,7,1]).reshape(2,2)
print(array2d)
print("\n")
# axis가 0일 때가 행(row)
# 오름차순을 행 방향으로 한다.
print(np.sort(array2d, axis=0))
print("\n")
# axis가 1일 때가 열(column)
# 오름차순을 열 방향으로 한다.
print(np.sort(array2d, axis=1))
원본 행렬이 정렬되었을 때, 기존 원본 행렬의 원소에 대한 인덱스를 필요로 할 때
np.argsort() 를 이용해서, 정렬 행렬 원본 행렬 인덱스를 ndarray로 반환합니다.
org_array = np.array ([3, 1, 9, 5])
sort_indices = np.argsort(org_array)
print(type(sort_indices))
print("정렬 시 인덱스 재배열 결과는 : ", sort_indices)
RDBMS : 관계형 데이터베이스 관리 시스템
하나의 person 이라고 하는 테이블 안에 이름, 나이, 동네 라고 하는 필드가 있고
그 안에 레코드라고 하는 독립적인 하나의 데이터들이 쌓입니다.
| 이름 | 나이 | 동네 |
| (…) | (…) | (…) |
각각의 데이터인 레코드들은 필드의 속성을 공유합니다.
같은 속성의 데이터들이 만들어지는 것이 기본적인 속성입니다.
정렬된 인덱스의 반환
넘파이의 RDBMS 는 테이블 칼럼이나 판다스의 데이터프레임 칼럼같은 데이터를 가질 수 없습니다.
즉 배열은 [ 1, 2, 3, 4 ] 이렇게 되어있으므로 필드 가 없습니다. 데이터를 표현할 데이터는 없고 인덱스만 있습니다.
실제 값과 그 값이 뜻하는 메타 데이터를 각각 가져야 합니다.
별도의 필드명 데이터가 필요하다는 의미입니다.
이름 array 따로, 나이 array 따로, 동네 array 따로 마련해야 합니다.
name_array = np.array(["김주성", "유진성" , "이은혜", "정원홍"])
score_array = np.array([75, 85, 84, 98])
# 넘파이의 팬시 인덱싱으로 이름 출력
sort_indices_asc = np.argsort(score_array)
print("성적 오름차순 정렬 시 성적 인덱스: ", sort_indices_asc)
print("성적 오름차순 정렬 결과 이름으로 출력: ", name_array[sort_indices_asc])
선형대수 연산
넘파이는 다양한 선형대수 연산을 지원합니다.
그 중 가장 많이 사용되면서 기본적인 행렬 내적(내적은 두 텐서(벡터) 간의 관계를 나타내는 데이터입니다.)과 전치 행렬을 구하는 방법을 알아보겠습니다.
행렬 내적은 행렬 간의 곱입니다. (행과 열의 수가 같아야 성립이 됩니다.)
전치 행렬이란 행과 열의 위치를 교환한 원소로 구성한 행렬입니다.
A = np.array([[1,2,3],[4,5,6]])
B = np.array([[7,8],[9,10],[11,12]])
dot_product = np.dot(A,B)
print("내적 결과 : \n", dot_product)
A = np.array([[1,2],[3,4]])
transpose_mat = np.transpose(A)
print("A의 전치행렬 : \n", transpose_mat)

여기까지 Numpy의 기본 배열과 연산에 대해서 알아보았습니다.
다음에는 판다스를 짧게 리뷰할게요.
'AI 머신러닝 딥러닝 > 파이썬 머신러닝 입문 공부일지' 카테고리의 다른 글
| 파이썬 머신러닝 입문 공부일지 5. Pandas 판다스 Index 객체 (1) | 2023.01.03 |
|---|---|
| 파이썬 머신러닝 입문 공부일지. 회귀 분석의 회귀란 무슨 뜻일까? (0) | 2023.01.02 |
| 파이썬 머신러닝 입문 공부일지 4. 판다스 Pandas, DataFrame 관련 메소드 기능들 (2) (0) | 2022.12.27 |
| 파이썬 머신러닝 입문 공부일지 3. 판다스 Pandas, DataFrame 관련 메소드 기능들 (1) (0) | 2022.12.27 |
| 파이썬 머신러닝 입문 공부일지 1. 머싱러닝의 시작 / Numpy 기본 함수 공부 (1) (0) | 2022.12.23 |