판다스Pandas
일반적으로 대부분의 데이터 세트는 2차원(행렬구조) 를 이루고 있습니다. (RDBMS : 관계형 데이터베이스 관리 시스템)
판다스는 R을 모티브로 만든 파이썬 라이브러리로 행과 열로 이루어진 2차원 데이터를 가장 효율적으로 가공/처리할 수 있는 가장 인기 있는 라이브러리 입니다.
파이썬의 리스트, 컬렉션, 넘파이 등의 내부 데이터 뿐만 아니라 CSV 등의 파일을 쉽게 DafeFrame 으로 변경하여 데이터를 가공/분석하기 편리하게 만들어줍니다.
DataFrame
판다스의 핵심 개체는 DataFrame데이터 프레임 입니다.
데이터 프레임은 여러 개의 행과 열로 이루어진 2차원 데이터를 담는 구조 입니다.

데이터 프레임은 중요한 객체인 Index와 유사한 Series 를 이해해야 합니다.
- Index는 RDBMS(관계형 데이터베이스 관리시스템) 의 PK(Primary Key)처럼 개별 데이터를 고유하게 식별하는 key입니다.
- Serise 시리즈는 데이터프레임의 하위 자료형으로 1개의 열이 시리즈고 이 시리즈가 다수 모여 데이터 프레임을 형성합니다.
- Serise와 DataFrame은 모두 Index를 key 값으로 가지고 있지만 다음과 같은 차이가 있습니다. 시리즈는 칼럼이 하나 뿐인 데이터 구조체이고, 데이터 프레임은 칼럼이 여러 개인 데이터 구조체라는 점입니다. 즉, 데이터 프레임은 여러 개의 시리즈로 이루어졌다고 할 수 있습니다.

판다스로 데이터 세트를 DataFrame 으로 로딩하기
판다스는 csv, tab 과 같은 다양한 유형의 분리 문자로 칼럼을 분리한 파일을 손쉽게 데이터 프레임으로 로딩합니다.
파일로 된 데이터 세트를 로딩할게요.
우선 주피터 노트북을 생성하고, 판다스 모듈을 임포트 합니다.
임포트 할 때 pandas 를 pd로 별칭(alias) 하는 것이 관례입니다.
import pandas as pd
다음으로는 캐글 홈페이지에서 우리가 사용할 데이터 세트를 다운로드 받습니다.
캐글은 2010년에 설립된 예측 모델 및 분석 대회 플랫폼으로 기억 및 단체에서 데이터와 해결과제를 등록하면, 데이터 과학자들이 이를 해결하는 모델을 개발하고 경쟁합니다.
즉, 기억이 캐글에게 빅데이터를 제공하면, 캐글은 이를 온라인에 공개하여 세계 각지의 수많은 데이터 사이언티스트들이 이 문제를 개인이나 팀으로 해결할 수 있도록 합니다.
https://www.kaggle.com/competitions/titanic
Titanic - Machine Learning from Disaster | Kaggle
www.kaggle.com
캐글 홈페이지에서 계정 생성 뒤에 로그인하여 '타이타닉 탑승자 파일' 을 다운로드 받아야 합니다.
해당 파일은 csv 형태로 제공되는데, 이 중 train.csv 를 클릭해서 주피터 노트북을 사용하고 있는 디렉터리로 titanic_train.csv 라는 파일명으로 변경하여 저장합니다.

해당 파일을 열어보면 맨 위에는 칼럼명이 나열되어 있고, 각각의 필드가 콤마(,) 로 분리되어 있습니다.
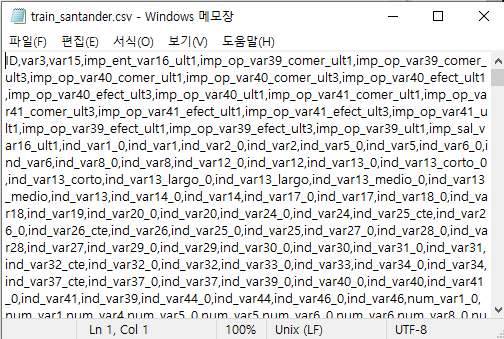
이제 이 데이터 세트를 데이터 프레임DataFrame 으로 로딩하겠습니다.
read_csv()
csv(칼럼을 , 콤마로 구분한 파일 포멧) 파일의 포멧 변환을 위한 API 입니다.
read_table() 과 read_csv() 의 차이점은 필드 구분 문자 Delimeter 가 '콤마,' 인지 탭'\t' 인지의 차이 입니다. (read_table() 은 탭으로 구분)
read_csv() 는 CSV 뿐 아니라, 어떤 필드 구분 문자 기반의 파일 포멧도 DataFrame 으로 변환할 수 있습니다.
read_csv()의 사용방법은 다음과 같습니다.
read_csv(filepath_or_buffer, sep=', ')
여기에서 filepath 를 지정하지 않으면 디폴트 값으로 할당되며, 파이썬 실행파일이 있는 디렉터리와 동일한 디렉터리에 있는 파일명을 로딩합니다.
titanic_df = pd.read_csv('./titanic_train.csv')
print('tatanic 변수의 type : ', type(titanic_df))
titanic_df
pd.read_csv() 는 호출하면 상기 이미지와 같은 DataFrame 객체로 반환합니다.
read_csv() 에는 다른 파라미터 지정이 없으면 파일의 맨 처음 row행을 칼럼명으로 출력합니다.
그리고 콤마로 분리된 데이터값들이 해당 칼럼에 맞게 할당 됩니다.
처음에 0, 1, 2, ... 로 순차적 표시 되어 있는 것는 것은 판다스의 Index 값입니다.
모든 DataFrame 내의 데이터는 생성되는 순간 고유의 index를 가집니다.
DataFrame.head()
데이터의 자료가 모두 출력되면 양이 많아지고 메모리도 크게 사용하므로 일부 데이터만 출력해볼게요.
DataFrame.head(n) 는 DataFrame 의 맨 앞에 있는 n개의 row만을 반환합니다.
titanic_df.head(3)

Shape
데이터 프레임의 행과 열의 크기를 알아보는 가장 좋은 방법은 데이터 프레임 객체의 shape 기능을 이용하면 됩니다.
shape 는 데이터 프레임의 행과 열을 튜플 형태로 반환합니다.
titanic_df.shape

우리가 다운로드 받은 '타이타닉 탑승자 명단' 은 총 891개의 로우와 12개의 칼럼으로 이루어져 있다는 것을 알 수 있습니다.
info(), describe()
데이터 프레임은 데이터 뿐만 아니라 칼럼의 타입, Null 데이터의 개수, 데이터 분포도 등의 조회 또한 가능합니다.
이를 위한 메소드로 우선 info()를 살펴봅니다.
titanic_df.info()
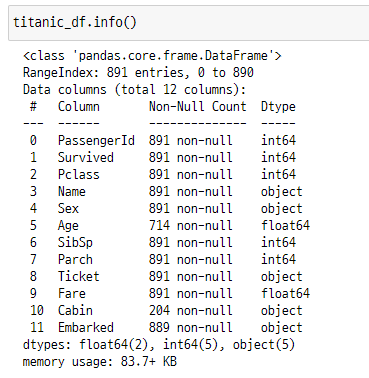
info() 메소드를 통해 전체 데이터 건수, 데이터 타입, Null 의 건수를 알 수 있습니다.
각 항목을 살펴봅니다.
- RangeIndex : 전체 row 의 수 . column 의 수
- Dtype : 칼럼별 데이터 타입. int, float 는 숫자형, object는 문자열
- Non-Null : 몇 개의 데이터가 Null 값이 아닌지 나타냄. Age의 경우 전체 891개의 데이터 중 714개의 데이터만 Null이 아니기 때문에 나머지 177개의 데이터는 Null의 값.
- 맨 아래 : 전체 12개의 칼럼들을 요약한 것으로 각 칼럼들의 type 을 일괄적으로 확인
다음은 titanic_df.describe() 입니다.

칼럼별 숫자형 데이터 값의 퍼센트 분포도, 평균값, 최댓값, 최솟값을 나타냅니다.
오직 int와 float 과 같은 숫자형의 분포도만 조사하며 자동으로 object 타입과 Null 데이터는 제외시킵니다.
각 항목들을 살펴봅니다.
- count : Not Null 데이터 건수
- mean : 전체 데이터의 평균 값
- srd : 표준 편차
- min : 최솟값
- max : 최댓값
- 25%, 50%, 75% : 각 25 percentile 값, 50 percentile 값, 75 percentile 값
그럼 여기에서 Pclass 객실 클래스의 값이 어떠한 분포로 구성되어 있는지를 확인해볼게요.
DataFrame 의 [ ] 내부에 칼럼명을 입력하면 시리즈 형태로 특정 칼럼 데이터 세트가 반환됩니다.
렇게 반환된 시리즈 객체에 value_counts() 메서드를 호출하면 해당 칼럼값의 유형과 건수를 확인할 수 있습니다.
value_counts()
value_counts() 는 데이터의 분포도를 확인하는데 매우 유용한 함수로 그룹화된 값을 기준으로 분포도를 확인합니다.
즉, 단일 칼럼으로 되어 있는 시리즈 Serise 객체에서 value_counts() 메소드를 호출하면 칼럼별 데이터 값의 분포도를 보다 명시적으로 확인할 수 있습니다.
value_counts() 는 데이터 프레임의 해당 칼럼만을 값으로 가지는 시리즈 객체를 보여줍니다.
value_counts = titanic_df['Pclass'].value_counts()
print(value_counts)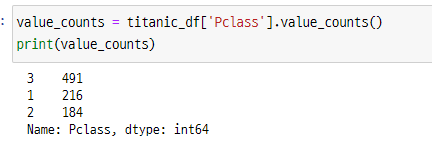
value_counts() 가 반환하는 데이터 타입은 시리즈 입니다.
왼쪽이 인덱스, 오른쪽이 데이터 값이 되지만 인덱스의 번호가 단순한 순차적 표현이 아닌 Pclass의 칼럼 값임을 알 수 있습니다.
이렇게 3등급 선실은 491개, 2등급 선실은 184개, 1등급 선실은 216개인 것을 확인할 수 있습니다.
단, value_counts() 메소드를 사용할 때에는 Null 값을 무시하고 결괏값을 내놓을 수 있으므로
Null 값을 포함해서 데이터 값을 계산할 것인지를 dropna 로 확인할 수 있습니다.
dropna 의 디폴트 값은 True 이며 Null 값을 무시하고 개별 데이터 값의 건수를 계산합니다.
print('titanic_df 데이터 건수:', titanic_df.shape[0])
print("")
print(titanic_df['Embarked'].value_counts())
print("")
print(titanic_df['Embarked'].value_counts(dropna=False))
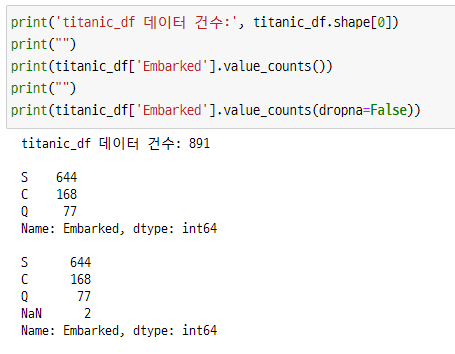
dropna를 False 로 처리하자 총 데이터 건수 891건 중에 Null 값을 포함된 2개를 발견할 수 있습니다.
[ ' 칼럼명 ' ] Series 객체 반환
데이터 프레임 [ ] 연산자 내부에 칼럼명을 입력하면 해당 칼럼에 해당하는 시리즈 객체를 반환합니다.
titanic_pclass = titanic_df['Pclass']
titanic_pclass.head()
여기에서 첫 번째 열인 0 1 2 3 4 는 시리즈의 index 값에 해당하고,
그 다음 열인 3 1 3 1 3 은 시리즈의 data 값에 해당합니다.
head() 안에 숫자를 넣으면 그 숫자만큼 앞의 갯수만 추출해서 출력할 것입니다.
우선 여기까지 알아본 뒤 다음에는 또 다른 기능들을 확인해볼게요.
'AI 머신러닝 딥러닝 > 파이썬 머신러닝 입문 공부일지' 카테고리의 다른 글
| 파이썬 머신러닝 입문 공부일지 5. Pandas 판다스 Index 객체 (1) | 2023.01.03 |
|---|---|
| 파이썬 머신러닝 입문 공부일지. 회귀 분석의 회귀란 무슨 뜻일까? (0) | 2023.01.02 |
| 파이썬 머신러닝 입문 공부일지 4. 판다스 Pandas, DataFrame 관련 메소드 기능들 (2) (0) | 2022.12.27 |
| 파이썬 머신러닝 입문 공부일지 2. Numpy 기본 함수 공부 (2) 넘파이 배열 인덱싱, 슬라이싱, 정렬과 선형대수 연산 (0) | 2022.12.23 |
| 파이썬 머신러닝 입문 공부일지 1. 머싱러닝의 시작 / Numpy 기본 함수 공부 (1) (0) | 2022.12.23 |