Pandas 의 index 객체에 대해서 RDBMS (관계형 데이터베이스 관리 시스템) 의 PK(Primary Key) 와 유사하게 사용된다는 것을 앞서 확인하였습니다.
https://blue-dot.tistory.com/178
파이썬 머신러닝 입문 공부일지 3. 판다스 Pandas, DataFrame 관련 메소드 기능들 (1)
판다스Pandas 일반적으로 대부분의 데이터 세트는 2차원(행렬구조) 를 이루고 있습니다. (RDBMS : 관계형 데이터베이스 관리 시스템) 판다스는 R을 모티브로 만든 파이썬 라이브러리로 행과 열로 이
blue-dot.tistory.com
index 객체 추출
데이터 프레임이나 시리즈에서 Index 객체만 추출하기 위해서는 DataFrame.index, Series.index 속성을 통해 가능합니다.
반환되는 index 의 값은 넘파이 1차원 ndarray 배열입니다.
index객체의 values 속성으로 ndarray 값을 확인할 수 있습니다.
우선 앞서 데이터 프레임을 삭제하고 수정하는 등 훼손된 부분이 많으니 titanic_df 를 다시 csv 로딩하겠습니다.
우리는 앞서 titanic_df.info() 를 통해 총 인덱스의 값이 891 건인 것을 확인했습니다.
만약 index 값을 넘파이 1차원 ndarray 배열로 확인한다고 한다면 891 개의 배열이 출력되어야겠죠.
기대하는 값이 나오는지 직접 코드를 통해서 확인해보겠습니다.
import pandas as pd
titanic_df = pd.read_csv('./titanic_train.csv')
indexes = titanic_df.index
print(indexes)
print("")
print("array 로 변환하여 보기 : \n\n", indexes.values)

0부터 890 index 까지 총 891 건의 1차원 array 를 확인할 수 있습니다.
배열 ndarray와 유사한 방법으로 [n] 으로 n번째 단일 값을 반환하거나, [n:n] 으로 슬라이싱이 가능합니다.
print(indexes.values.shape)
print("")
print(indexes[:5].values) # 슬라이싱 후 values 로 배열 변환
print(indexes.values[:5]) # values 로 배열 변환 후 슬라이싱
# 상기 코드 둘 다 같은 결과를 반환합니다.
print("")
print(indexes[6]) # 6번째 배열의 인덱스 반환
다만 데이터 프레임과 시리즈는 불변성을 지니고 있기 때문에 객체는 함부로 변경할 수 없습니다.
즉 indexes[0] = 5 와 같이 0 번째 인덱스의 값을 5로 변경하고 싶어도 해당 작업은 수행할 수 없습니다.
데이터 프레임이나 시리즈에 reset_index() 메소드를 수행하면 새로운 인덱스를 연속적인 숫자 형으로 할당할 수 있습니다.
이 경우에 기존에 존재하던 index 는 index 라는 칼럼명으로 새롭게 추가 되고, 새로 생성된 index 는 칼럼명 없이 할당 됩니다.

reset_index() 는 기존의 인덱스가 연속된 숫자형 인덱스가 아닐 경우에
연속 숫자형 인덱스로 만들기 위해서 주로 사용됩니다.
reset_index() 의 파라미터에 drop=True 를 입력하면 기존 인덱스는 새로운 칼럼으로 추가되는 것이 아니라 삭제(Drop)됩니다. 새로운 칼럼이 추가되지 않으므로 그대로 시리즈를 유지할 수 있습니다.
데이터 셀렉션(선택)
넘파이Numpy의 경우 [ ] 연산자 내에 단일값 추출, 인덱싱, 슬라이싱 등을 통해 데이터를 추출합니다.
판다스Pandas의 경우 iloc[ ] , loc[ ] 연산자를 통해 동일한 작업을 수행합니다.
- iloc [ ] 는 integer location 의 약어로 행이나 칼럼의 순서를 나타내는 정수로 특정 값을 가져옵니다. df.iloc[행 인덱스, 열 인덱스] 의 형식으로 사용합니다. 컴퓨터가 읽기 좋은 숫자 표기법으로 데이터가 있는 위치에 접근합니다.
- loc [ ] 는 칼럼명을 직접 적거나, 특정 조건식을 써줘서 사람이 읽기 좋은 방법으로 데이터에 접근합니다.
- DataFrame 뒤에 [ ] 연산자가 바로 들어오는 경우에는 칼럼명 문자(칼럼명의 리스트 객체) 또는 인덱스로 변환 가능한 표현식이 올 수 있습니다.
예를 들어 df.loc[0] 은 전체 데이터 프레임에서 인덱스 이름이 0 인 행만 추출한다. 라는 의미라면
df.iloc[0] 은 전체 데이터 프레임에서 0 번째 행에 있는 값들만 추출한다. 라는 의미가 됩니다.
df[0] 은 0 의 칼럼만 지정할 수 있는 칼럼 지정 연산자가 됩니다.
데이터 프레임 바로 뒤에 [ ] 연산자가 오는 경우
우선 df[ 0 ] 처럼 데이터 프레임 바로 뒤에 [ ] 연산자가 오는 경우에 대해서 실제 코드를 보면서 확인해보겠습니다.
print(titanic_df['Pclass'].head(3))
print("")
print(titanic_df[['Pclass', 'Survived']].head(3))
print("")
titanic_df[ 0:2 ]
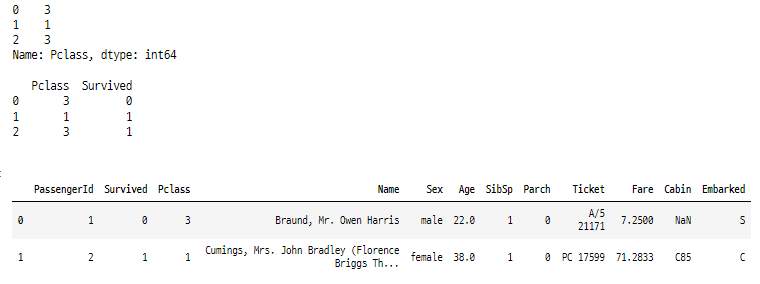
특정 칼럼과 로우만 선택된 것을 확인할 수 있습니다.
데이터 셀렉션은 불린 인덱싱 표현도 가능합니다.
불린 인덱싱은 기존에 한 번 개념적으로만 살펴본 적이 있었습니다.
https://blue-dot.tistory.com/177
파이썬 머신러닝 입문 공부일지 2. Numpy 기본 함수 공부 (2) 넘파이 배열 인덱싱, 슬라이싱, 정렬과
앞서 Numpy 넘파이의 기본 배열 함수에 대해서 알아보았습니다. 이번에는 선택자 함수인 인덱싱과 슬라이싱 그리고 정렬에 대한 것을 알아보겠습니다. Numpy의 선택함수 인덱싱, 슬라이싱 ndarray 인
blue-dot.tistory.com
[ ] 내의 불린 인덱싱은 원하는 데이터를 편하게 추출해주기 때문에 자주 사용 됩니다.
가령 Pclass 선실 등급 중 3등급인 자료들만 확인하고 싶을 때 데이터 프레임의 칼럼을 선택한 뒤 그 데이터 값이 3인지 여부를 확인하여 True 라면 출력할 수 있도록 표현식을 작성할 수 있습니다.
titanic_df[ titanic_df['Pclass'] == 3 ].head(3)
여기까지 한 번 [ ] 연산자에 대한 정리한 뒤에 넘어갈게요.
- DataFrame 바로 뒤에 존재하는 [ ] 연산자는 넘파이의 [ ] 나 시리즈의 [ ] 와 다릅니다. 이는 칼럼명을 지정해 칼럼 지정 연산에 사용하거나 불린 인덱스 용도로만 사용합니다.
데이터 프레임 iloc [ ] 연산자
iloc [ ] 연산자는 위치 기반Location 인덱싱 방식으로 동작합니다.
행과 열의 위치를 0에서 출발하는 세로축과 가로축 좌표 정숫값으로 지정합니다.
해당 연산자를 확인하기 위해 딕셔너리 형태로 만든 간단한 데이터 프레임을 생성해봅니다.
key의 값이 컬럼이 되며, value 의 값이 칼럼의 데이터로 맵핑됩니다.
data = {'Name': ['솔라', '파비','도도', '레미'],
'Year': [2020, 2021, 2022, 2023],
'Gender': ['Male', 'Female', 'Male', 'Male']
}
data_df = pd.DataFrame(data, index=['one','two','three','four'])
data_df
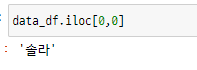
여기에서 첫 번째 행, 첫 번째 열의 데이터를 iloc[ ] 를 통해 추출해봅니다.
iloc[ ] 는 숫자를 기반으로 하기 때문에 문자열을 넣으면 오류가 발생합니다.
data_df.iloc[0,0]
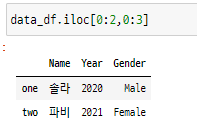
- data_df[2, 1] = 세 번째 행의 두 번째 열 위치에 있는 단일 값 반환

- data_df.iloc[0:2, [0,1]] = 0:2 슬라이싱 범위의 첫 번째에서 두 번째 행과 첫 번째, 두 번째 열에 해당하는 값 반환

- data_df.iloc[0:2, 0:3] = 0:2 슬라이싱 범위의 첫 번째에서 두 번째 행의 0:3 슬라이싱 범위의 첫 번째부터 세 번째 열 범위에 대항하는 값 반환
데이터 프레임 loc [ ] 연산자
loc [ ] 연산자는 명칭Label 기반 인덱싱 방식으로 동작합니다.
데이터 프레임의 인덱스 값으로 행 위치를, 칼럼의 명칭으로 열 위치를 지정합니다.
인덱스 값이 one 인 행의 칼럼명이 Name 인 데이터를 추출해봅니다.

위에서 활용해보았던 iloc[ ] 연산자와 다른 것은 '명칭'을 기반으로 하기 때문에 문자열로 인덱스를 구분하는 것이 특징적입니다.
여기서 iloc [ ] 와 loc [ ] 에 대한 정리를 한 번 하고 넘어갑니다!
- 칼럼 값 전체를 추출하고자 한다면 data_df['Name'] 과 같이 데이터프레임['칼럼명'] 만으로 호출한다.
- iloc[ ] 는 위치 기반 인덱싱만 가능하므로 행과 열 위치의 값을 정수형 값으로 지정하여 데이터를 반환한다.
- loc[ ] 는 명칭 기반 인덱싱만 가능하므로 행 위치에 데이터 프레임 인덱스가 오며, 열 위치에는 칼럼명을 지정해 데이터를 반환한다.
데이터 필터링 (불린 인덱싱)
불린 인덱싱은 [ ] 와 loc [ ] 에서 공통으로 지원합니다. (iloc [ ] 는 정수값만 지원하기 때문에 확인되지 않습니다.)
이전에 활용하던 타이타닉 데이터 세트에서 승객 중 나이가 60세 이상인 승객만 조회해보겠습니다.
우선 데이터 프레임 중 Age 칼럼만 인덱싱 한 후 불린 인덱싱으로 '60 이상' 이라는 조건식을 넣습니다.
titanic_bool = titanic_df[titanic_df['Age'] > 60]
titanic_bool.head(3)
반환된 결과값은 데이터 프레임이므로 해당 반환 객체에서 원하는 칼럼명만 별도로 추출하는 것도 가능합니다.
나이 60세 이상의 승객 중 이름을 추출해보겠습니다.
앞서 배웠던 것처럼 데이터 프레임 바로 뒤에 오는 [ ] 를 사용합니다.
단, 칼럼이 두 개 이상이므로 [ [ ] ] 로 중첩해서 사용합니다.
titanic_df[titanic_df['Age'] > 60][['Name','Age']].head(3)

이렇게 조건식을 여러 개를 사용하여 조회할 수도 있습니다.
- and 조건은 &
- or 조건은 | ( 엔터 위 달러 표시를 Shift 키를 누른 채 입력)
- Not 조건은 ~
'AI 머신러닝 딥러닝 > 파이썬 머신러닝 입문 공부일지' 카테고리의 다른 글
| 파이썬 머신러닝 입문 공부일지 7. 결손 데이터 Null Data 처리하기 (0) | 2023.01.03 |
|---|---|
| 파이썬 머신러닝 입문 공부일지 6. 판다스 DataFrame 정렬, Aggregation, GroupBy (0) | 2023.01.03 |
| 파이썬 머신러닝 입문 공부일지. 회귀 분석의 회귀란 무슨 뜻일까? (0) | 2023.01.02 |
| 파이썬 머신러닝 입문 공부일지 4. 판다스 Pandas, DataFrame 관련 메소드 기능들 (2) (0) | 2022.12.27 |
| 파이썬 머신러닝 입문 공부일지 3. 판다스 Pandas, DataFrame 관련 메소드 기능들 (1) (0) | 2022.12.27 |