이제 BeautifulSoup 로 웹사이트의 데이터를 추출하는 것을 해볼게요.
전에 파이썬에서도 해봤지만 조금 더 자세히 보겠습니다.
웹 상에서 정보를 본다, 라고 할 때 웹과 인터넷은 동의어가 아닙니다.
인터넷이라는 망 안에서 정보를 교환하기 위해 사용되는 프로그램이 '웹' = 소프트웨어 입니다.
www.naver.com 이라고 검색을 해서 웹 서핑을 할 때
입력하는 창을 주소창이라고 합니다. = url (Uniform Resource Locator)
주소창에 주소를 입력하고 엔터를 누를 때 서버의 정보를 요청을 하고 그에 www.naver.com 에서는 응답을 통해 정보를 전송합니다.
만약 어떤 웹 사이트에서 정보를 가져오고 싶을 때 우리가 익히 알고 있는 문자열 함수로는 웹 사이트의 코드에서 추출해서 오는 것에 한계가 있으므로 BeautifulSoup를 활용합니다.
BeautifulSoup 모듈을 사용할 때, 우선 requests 로 자료를 요청해서 가져오는 것이 순서입니다.
import requests
# 정보를 요청하고자 하는 웹 페이지의 주소를 기억한다.
url = "http://www.naver.com/"
# 웹페이지가 저장된 서버에 요청을 보내고, 그에 따른 응답을 기억한다.
response = requests.get(url)
# 이것을 확인한다.
print(response)<Response [200]>결과값에 있는 200 이라는 숫자는 requests 로 자료를 요청했을 때 응답이 어떻게 처리되었는지를 확인하는 것입니다.
요청에 따른 응답의 숫자 코드 !
- 200 번대의 응답코드 : 정상처리
- 400 번대의 응답코드 : 요청 시 문제 발생 (코드 작성자 측 문제)
- 500 번대의 응답코드 : 응답 시 문제 발생 (서버 측 문제)
그럼 requests 로 응답을 받아서 그 코드값을 BeautifulSoup 로 분석해볼게요. (코드 텍스트화!)
import requests
from bs4 import BeautifulSoup
# 정보를 요청하고자 하는 웹 페이지의 주소를 기억한다.
url = "http://www.naver.com/"
# 웹페이지가 저장된 서버에 요청을 보내고, 그에 따른 응답을 기억한다.
response = requests.get(url)
# 이것을 확인한다.
code = response.text
# 코드를 분석한 결과를 얻는다.
soup = BeautifulSoup(code, "html.parser")
print(soup)
url의 응답 값을 code 로 분석해서 가져왔어요.
이제 분석했으니 원하는 값을 분석해서 수프를 만들어볼게요.
네이버 증권 페이지에서 코스피 지수 값만 불러오겠습니다.

저는 네이버 금융 메인 페이지에서 오늘의 코스피를 가져오겠습니다.
저 페이지에서 F12를 누르면 개발자 페이지가 뜹니다.

저 화살표를 누르면 클릭을 통해서 그 페이지 안에 있는 소스를 특정해서 볼 수 있습니다.
한번 클릭하면 파란색으로 아이콘이 변합니다.
아이콘이 파란색일 때 코스피의 파란색 글자(ㅠㅠ) 지수를 클릭하면 옆에 해당 값의 코드가 뜹니다.

태그를 읽고 bs4에서 표현하는 방법은
<span> </span> <- 으로 되어 있을 때 span 태그에 있는 하나의 값을 보는 것이에요.
태그 하나가 정보 하나(요소 하나)를 담당합니다.
태그는 이름이 겹치는 경우가 있더라도 class 로 역할을 나눠서 구별할 수 있고, 그 안에서 id로도 구분할 수 있습니다.
즉, 태그는 class와 id로 구분합니다.
#은 id
.은 class 로 기재합니다.
즉
...
<a id = "one">
...
..
<span class"gg" > 닉네임 </span>
...
</a>
...
"a#one > span.gg"으로 되어 있을 때 (a 태그 안에 있는 one id 에서 클래스 gg 가 붙어있는 span 태그 검색!) 으로 읽을 수 있어요.
클래스 사이에 공백이 있으면 클래스 여러 개가 따로 있는 것이고, 그 중에 하나만 불러와도 수프는 완성 됩니다.
그럼 저 안에서 코스피 지수를 가져와 볼게요
import requests
from bs4 import BeautifulSoup
# 네이버 금융 소스 코드 얻기
url = "https://finance.naver.com/" #어떤 url 에서 얻어올 것인지
response = requests.get(url) #requests 를 통해 요청정보를 받는다.(응답값)
code = response.text # 응답 값을 .text 로 문자열로 만들어 code 변수에 저장
# 소스 코드 분석하기
soup = BeautifulSoup(code, "html.parser")
# 태그를 검색하기
tag = soup.select_one("span.dn > span.num") #클래스가 dn 인 span 태그에 포함되어 있다.
# 출력하기
print(tag.string) # 내용이 없거나 태그가 섞여 있으면 None 이 출력된다.
# 태그가 포함되어 있어도 None 이 출력 된다.
print(tag.text) # 내용이 없거나 태그가 섞여있어도 문자열이 나온다.
# 태그가 포함되어 있어도 문자열이 나오고, 공백은 빈 문자열이 나온다.2,212.73
2,212.73이렇게 결과값을 불러올 수 있습니다.
그럼 이것을 응용해서 네이버 영화 관련 기사에서 특정 검색어를 입력해서 뉴스 기사 제목을 얻어오는 것을 해볼게요.
페이지는 하단과 같습니다.
https://entertain.naver.com/movie
영화 :: 네이버 TV연예
지금 가장 핫한 연예 이야기
entertain.naver.com
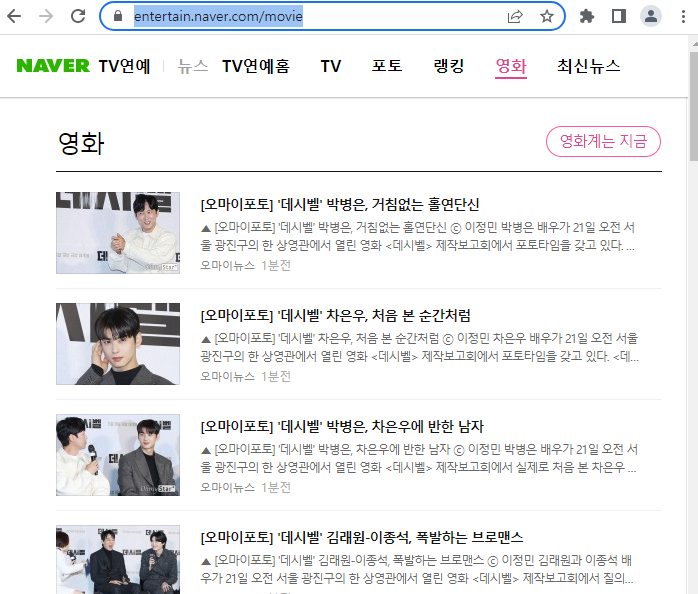
차은우가 데시벨 영화를 촬영했나봐요.. 전부 데시벨 이야기 밖에 없네요. ..........
그럼 여기서 차은우를 검색하는 코드를 짜보겠습니다..
우선 input 함수로 키워드를 입력 받고, 그것이 포함된 내용을 검색하도록 해볼게요.

기사 제목을 누르니 html 코드가 뜹니다.
이제 bs4로 기사 제목만을 추출해올게요.
import requests
from bs4 import BeautifulSoup
url = "https://entertain.naver.com/movie"
response = requests.get(url)
code = response.text
soup = BeautifulSoup(code, "html.parser")
tags = soup.select("a.tit") # a.tit 가 포함되는 태그들을 모두 가져온다.
a = input("키워드를 입력하세요 > ")
for tag in tags : # 가져온 모든 태그들을 반복문을 통해 출력한다.
if a in tag.text :
print(tag.string)이제 키워드에 차은우를 입력했을 때 차은우 관련 기사만 뜨는지 볼게요!
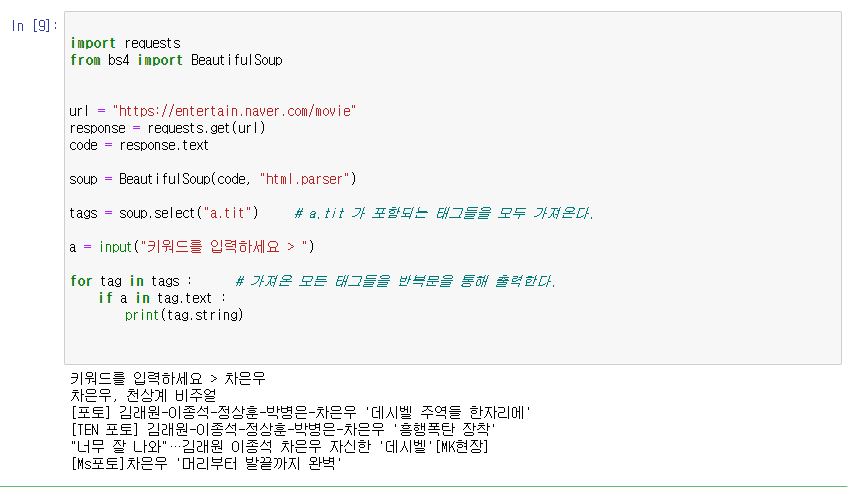
야호... 결과가 예쁘게 나오네요 ^^...
bs4 연습은 여기까지 해볼게요!

'AI 머신러닝 딥러닝 > AI 수학 입문 공부일지' 카테고리의 다른 글
| AI 인공지능 수학 공부일지 6. 거듭제곱, 제곱근, 삼각함수, 난수 그래프 그리기 (0) | 2022.10.24 |
|---|---|
| AI 인공지능 수학 공부일지 5. matplotlib 기초 (0) | 2022.10.21 |
| AI 인공지능 수학 공부일지 4. Numpy 기초 행열 (0) | 2022.10.21 |
| AI 인공지능 수학 공부일지 3. 판다스 pandas 모듈 (0) | 2022.10.21 |
| AI 인공지능 수학 공부일지 1. 파이썬 개발 환경 아나콘다Anaconda 설치하기, 주피터 Jupyter 실행하기 (0) | 2022.10.21 |