apply lambda 람다식
판다스는 apply 함수에서 lambda람다식을 활용해서 데이터를 가공하는 기능을 제공합니다.
람다는 매개변수로 함수를 전달하기 위해 함수 구문을 작성하는 것이 코드가 길어지고 번거롭기 때문에
조금 더 간단하게 함수를 선언하기 위해 만들어진 구문입니다.
https://blue-dot.tistory.com/22
파이썬 공부일지 19. 함수 활용 (튜플, 람다)!
다음으로 함수 관련하여 편하게 쓸 수 있는 기능들로 튜플과 람다가 있습니다. 1. 튜플 리스트와 비슷한 자료로 리스트와 다른 점으로는 한 번 결정된 요소는 바꿀 수 없다는 것입니다. a = [ 요소
blue-dot.tistory.com
lambda 구문형식
lambda의 구문 형식은 다음과 같습니다.
함수명 = lambda 매개변수 1, 2, ... : 매개변수_표현식
: 를 사용해서 입력인자와 적용될 계산식을 분리합니다.
result = lambda x : x ** 2
print( result(3) )해당 코드를 실행하면 9 가 반환됩니다.
상기 코드에서 x는 매개변수 이며, x ** 2 는 입력인자가 게산될 계산식입니다.

lambda 식을 이용할 때에는 여러 개의 값을 입력 인자로 사용해야 할 경우 보통 map() 함수와 결합해서 사용합니다.
map()
map() 함수를 사용하면 리스트의 인자 수 만큼 입력을 바꾸면서 반복적으로 함수를 호출할 수 있습니다.
map() 함수 안에 lambda 를 삽입하여 리스트 의 인자 수 만큼 계산식을 적용합니다.
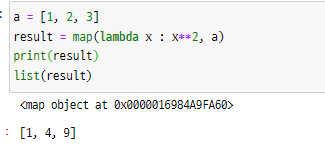
해당 값은 map 의 형식으로 출력되기 때문에 print() 가 아닌 list() 로 반환값을 확인할 수 있습니다.
a = [1, 2, 3]
result = map(lambda x : x**2, a)
print(result)
list(result)
apply.(lambda 적용)
판다스에서는 전체 데이터 변환을 쉽게 해주는 기능을 제공하는데 그 중 하나가 apply 함수 입니다.
apply 함수의 첫 번째 인자에는 적용하고자 하는 함수를 넣어주고, axis를 1(행)으로 할지 0(열)로 할지를 적용합니다.
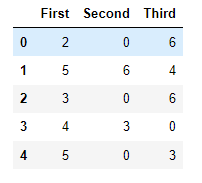
만약 다음과 같은 데이터 프레임이 있다고 가정합니다.
여기에 행(로우) 별로 평균을 구하고 싶다면 apply 함수를 통해 데이터 프레임 전체에 함수식을 적용할 수 있습니다.
import numpy as np
df.apply(np.mean, axis=1)
넘파이의 메소드 중 mean 평균을 구하는 기능을 axis=1 전체 행에 apply 로 데이터 프레임에 적용합니다.

판다스는 데이터 프레임의 apply에서 lambda 식을 적용해서 데이터를 가공할 수 있는 기능을 제공합니다.
우리가 앞서 예시로 사용하고 있는 타이타닉 탑승자 명단을 이용해서 데이터를 가공해보겠습니다.
탑승객들의 이름의 문자열 개수(길이)를 계산하는 것을 적용해볼게요.
'Name_len' 이라는 칼럼을 추가하고
그 안에는 lambda 식을 사용하여 'Name' 컬럼에 apply로 가공한 칼럼 데이터를 저장할게요.
lambda 식으로는 len()함수를 통해 각각 대입되는 값 마다 길이를 계산합니다.
titanic_df['Name_len'] = titanic_df['Name'].apply(lambda x : len(x))
titanic_df[['Name', 'Name_len']] .head(3)
이름과 이름의 길이가 기재된 컬럼이 추가되어 반환됩니다.
이번에는 좀 더 심화된 lambda 식을 활용해보겠습니다.
탑승객 중 나이가 15세 미만이면 Child 그렇지 않으면 Adult 로 구분하는 C/A 칼럼을 만들어봅니다.
여기에서는 조건문이 추가되어야 하므로 lambda 식에 if else 절이 사용되어야 합니다.
if else 를 사용할 때에는 파이썬에 없는 3항 연산식을 대체할 코드를 작성합니다.
[True] if [Condition] else [False]
[참일때] if [조건문] else [거짓일때]
코드를 보면서 확인해볼게요.
titanic_df['C/A'] = titanic_df['Age'].apply(lambda x : 'Child' if x <= 15 else 'Adult')
titanic_df[['Age', 'C/A']].head(10)

새로운 C/A 칼럼이 추가 되고 Adult 와 Child 가 나누어진 것을 확인할 수 있습니다.
여기에서 주의할 것은 if, else 만 지원하며 if, else if, else if 는 지원하지 않으므로
else if 역할을 하는 조건식을 사용하고 싶다면 else 에 해당하는 절을 ( ) 로 내포해서 ( ) 에서 다시 if else 를 적용하는 방법을 사용해야 합니다.
다음으로 15세 이하는 Child , 15~60세 사이는 Adult, 61세 이상은 Elderly 로 분류하는 C/A/D 칼럼을 추가하고
해당 인원이 몇 명이 되는지 그 값을 카운트하겠습니다.
titanic_df['C/A/D'] = titanic_df['Age'].apply(lambda x : 'Child' if x <= 15
else ('Adult' if x <= 60 else 'Elderly'))
titanic_df['C/A/D'].value_counts()

이렇게 apply lambda 식을 통해서 데이터를 일괄적으로 가공하고 저장하는 역할을 할 수 있습니다.
여기까지 판다스의 기본적인 기능들을 살펴보았습니다.
다음에는 사이킷런을 사용하는 방법과 활용 예제들을 볼게요.
'AI 머신러닝 딥러닝 > 파이썬 머신러닝 입문 공부일지' 카테고리의 다른 글
| 파이썬 머신러닝 입문 공부일지 10. 첫 번째 머신러닝 만들기 - 붓꽃 품종 예측하기 (2) (0) | 2023.01.04 |
|---|---|
| 파이썬 머신러닝 입문 공부일지 9. 사이킷런 기초 시작하기 (사이킷런 설치하기, 첫 번째 머신러닝 만들기 - 붓꽃 품종 예측하기) (1) (0) | 2023.01.04 |
| 파이썬 머신러닝 입문 공부일지 7. 결손 데이터 Null Data 처리하기 (0) | 2023.01.03 |
| 파이썬 머신러닝 입문 공부일지 6. 판다스 DataFrame 정렬, Aggregation, GroupBy (0) | 2023.01.03 |
| 파이썬 머신러닝 입문 공부일지 5. Pandas 판다스 Index 객체 (1) | 2023.01.03 |