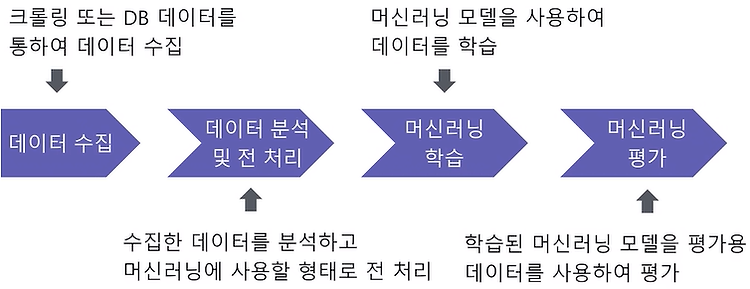
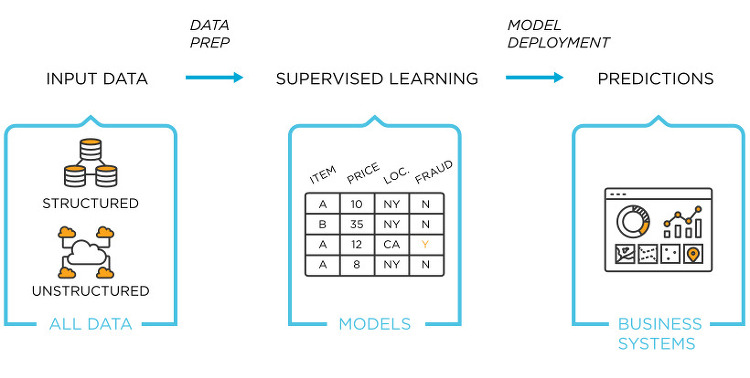
이전까지 전처리 과정과 데이터 탐색을 마쳤으므로 이번에는 데이터 가공을 해보겠습니다. 데이터 가공 1. Survived 속성 별도 분리 후 클래스 결정값 데이터 세트로 설정 (학습 데이터 생성) 원본 CSV 데이터를 다시 로딩한 뒤, 피처 데이터 세트와 레이블 데이터 세트 추출 생성된 데이터 세트에 transform_features() 함수로 일괄 데이터 가공합니다. titanic_df = pd.read_csv('./titanic_train.csv') # 재로딩 y_titanic_df = titanic_df['Survived'] # Survived 값만 별도로 y 값 지정 X_titanic_df= titanic_df.drop('Survived',axis=1) # 기존 칼럼 삭제 후 새 칼럼 생성 X_ti..