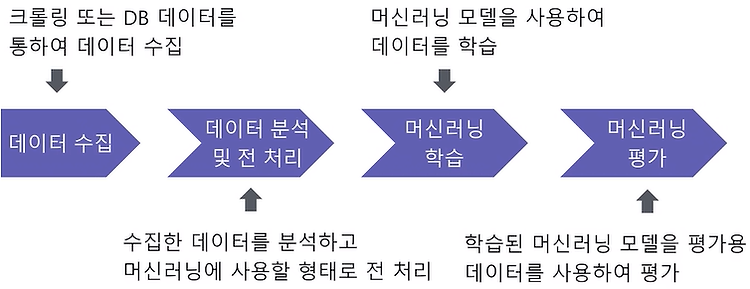
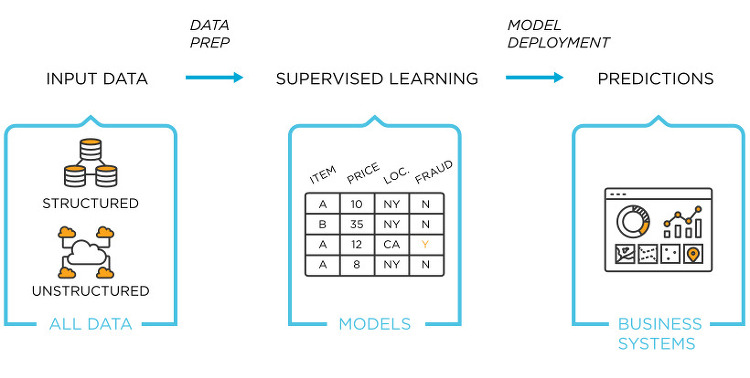
Grayscale 이미지로 출력 cvtColor 함수를 이용하여 그레이 스케일 영상으로 변경할 수 있습니다. import cv2 from matplotlib import pyplot as plt imageFile = './data/lena.jpg' imgGray = cv2.imread(imageFile, cv2.IMREAD_GRAYSCALE) plt.axis('off') plt.imshow(imgGray, cmap ="gray", interpolation = 'bicubic') # 보간(빈곳을 채운다) plt.show() interpolation 설정값은 보간 입니다. 이미지 보간법(interpolation) 영상 변환 작업 시 아무런 정보를 받지 못하는 화소를 홀(hole) 이라고 부릅니다. 이러한 홀..