사이킷런은 모델학습을 위해 다양한 알고리즘 구현 프레임워크를 제공합니다.
그 중 이번에는 지도학습과 사이킷런 주요 모듈에 대해서 알아볼게요.
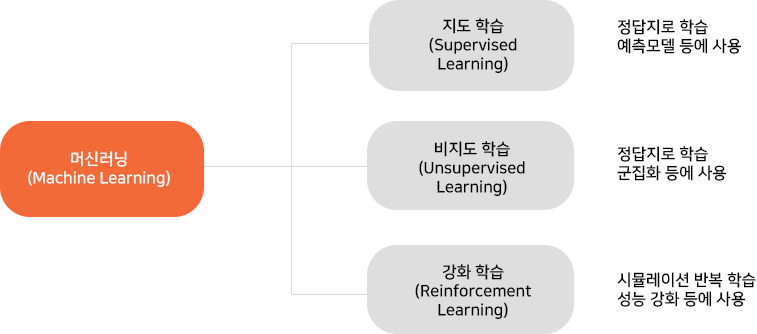
지도학습
지도 학습이란 데이터에서 반복적으로 학습하는 알고리즘을 사용해서 컴퓨터가 어디를 봐야 하는지를 명시적으로 프로그래밍을 하지 않고도 숨겨진 통찰력을 찾을 수 있도록 하는 데이터 분석 방법입니다.
지도 학습은 알려진 문제를 해결하고, 레이블이 지정된 데이터 세트를 사용해서 특정 작업을 수행할 수 있도록 알고리즘을 훈련시킵니다.

지도학습의 중요 두 축은 분류 Calssfication 과 회귀 Regression 입니다.
주어진 입력 벡터가 어떤 종류인지를 구분하는 것을 분류이고,
훈련 데이터를 통해 유추된 함수 중 연속적인 값을 출력하는 것이 회귀입니다.
분류는 이산 변수(고정된 수의 고유값만 가질 수 있고 고유한 순서가 없는 통계변수) 에 대한 입력 데이터를 분류하도록 알고리즘을 훈련하는 학습 방법입니다.
예를 들면, 데이터는 고객세트의 마지막 신용 카드 청구서로 구성되며 향후 구매 여부가 표시될 때, 새로운 고객의 신용 잔고가 알고리즘에 제시되면 고객을 '구매할 고객'과 '구매하지 않을 고객'으로 분류합니다.
회귀는 가능한 연속 갓 범위에서 출력을 예측하도록 알고리즘 훈련을 하는 지도 학습 방법 입니다. 회귀 알고리즘의 정확성은 정확한 출력과 예측된 출력 간의 분산을 기반으로 계산됩니다.
예를 들면, 부동산 교육 데이터는 위치, 면적 기타 관련 매개변수를 기록하고, 산출물은 특정 부동산의 가격을 정했을 때 위치와 면적에 따른 부동산의 가격을 회귀로 예측합니다.
지도 학습에는 Estimator 클래스가 있습니다.
사이킷런 클래스는 모델학습을 위한 fit() 메소드와 학습 모델 예측을 위한 predit() 메소드 만으로 간단하게 학습과 예측 결과를 반환합니다.
분류 알고리즘을 구현한 클래스를 Classifier (분류) 로, 회귀 알고리즘을 구현한 클래스를 Regressor(회귀) 로 지칭하며, 이 둘을 합쳐서 에스티메이터 Estimator 클래스 라고 부릅니다.

사이킷런에서는 교차검증을 더 쉽게 할 수 있도록 제공하는 API가 있는데 그것이 바로 cross_val_score() 입니다.
cross_val_score() 는 여러가지 인자를 받을 수 있지만, 그 중에서도 Estimator를 인자로 받습니다.
즉, 분류 알고리즘Classifier 인지 회귀 Regressor 인지를 구분하며,
이 Estimator 안에 있는 fit() 과 predict() 를 호출해서 평가를 하거나 하이퍼 파라미너 튜닝을 합니다.
비지도학습
비지도학습의 알고리즘은 정답 lable 없이 데이터를 학습 합니다. 이것은 개입이 없는 데이터를 스스로 학습하여 그 속의 패턴 또는 각 데이터 간의 유사도를 학습합니다.
대표적인 기능으로 차원 축소, 클러스터링, 피처 추출 등이 있습니다.
- 차원 축소는 차원이 높은 데이터의 학습을 조금 더 효율적이게 하기 위해 사용되는 기술로, 고차원의 데이터를 저차원의 데이터로 만드는 것이 목표입니다.
- 클러스터링은 정해진 분류 없이 기계가 스스로 데이터들을 보고 학습하며 비슷한 특징의 데이터들끼리 군집화 시키는 기술입니다.
- 피처 추출은 해당 데이터의 특징 집합에서 일부를 제거하거나 선택해서 간결해진 특징의 집합을 뽑아내는 것입니다.
비지도학습 역시 대부분 fit() 과 transform()을 적용합니다.
비지도학습에서 fit()은 지도학습의 fit() 과 같이 학습을 의미하는 것이 아니라,
입력 데이터의 형태에 맞춰 데이터를 변환하기 위한 사전 구조를 맞추는 작업입니다.
fit() 으로 변환을 위한 사전 구조 작업을 맞추면 입력 데이터의 차원 변환, 클러스터링, 피처 추출 등의
실제적인 작업은 transform() 으로 수행합니다.
사이킷런 주요 모듈
아래는 사이킷런의 주요 모듈 요약입니다.
일반적으로 머신러닝 모델을 구축하는 주요 프로세스는
피처의 가공, 변경, 추출을 수행하는 피처 처리와 머신러닝 알고리즘 학습과 예측 수행,
모델 평가의 단계를 반복적으로 수행하는 것입니다.
사이킷런 패키지의 주요 모듈은 이러한 과정들을 편리하게 수행할 수 있는 API를 제공하니
주요 모듈들에 대해서는 한 번 보고 가는 것이 좋습니다.
| 분류 | 모듈명 | 설명 |
| 예제 데이터 | sklearn.datasets | 사이킷런에 내장되어 예제로 제공하는 데이터 세트 |
| 피처처리 | sklearn.preprocessing | 데이터 전처리에 필요한 다양한 가공 기능 제공(문자열을 숫자형 코드 값으로 인코딩, 정규화, 스케일링 등) |
| sklearn.feature_selection | 알고리즘에 큰 영향을 미치는 피처를 우선순위대로 셀렉션 작업을 수행하는 다양한 기능 제공 | |
| sklearn.feature_extraction | 텍스트 데이터나 이미지 데이터의 벡터화된 피처를 추출하는데 사용됨. 예를 들어 텍스트 데이터에서 Count Vectorizer나 Tf-Idf Vectorizer 등을 생성하는 기능 제공. 텍스트 데이터의 피처 추출은 sklearn.feature_extraction.text 모듈에, 이미지 데이터의 피처 추출은 sklearn.feature_extraction.image 모듈에 지원 API가 있음 |
|
| 피처 처리 & 차원 축소 | sklearn.decomposition | 차원 축소와 관련한 알고리즘을 지원하는 모듈이다. PCA, NMF, Truncated SVD 등을 통해 차원 축소 기능을 수행할 수 있다. |
| 데이터 분리, 검증 & 파라미터 튜닝 | sklearn.model_selection | 교차 검증을 위한 학습용/테스트용 분리, 그리드 서치(Grid Search)로 최적 파라미터 추출 등의 API 제공 |
| 평가 | sklearn.metrics | 분류, 회귀, 클러스터링, 페어와이즈(Pairwise)에 대한 다양한 성능 측정 방법 제공 Accuracy, Precision, Recall, ROC-AUC, RMSE 등 제공 |
| ML 알고리즘 | sklearn.ensemble | 앙상블 알고리즘 제공 랜덤 포레스트, 에이다 부스트, 그래디언트 부스팅 등을 제공 |
| sklearn.linear_model | 주로 선형 회귀, 릿지(Ridge), 라쏘(Lasso) 및 로지스틱 회귀 등 회귀 관련 알고리즘을 지원. 또한 SGD(Stochastic Gradient Desccent) 관련 알고리즘도 제공 | |
| sklearn.naïve_bayes | 나이브 베이즈 알고리즘 제공. 가우시안 NB. 다항 분포 NB 등 | |
| sklearn.neighbors | 최근접 이웃 알고리즘 제공. K-NN(K-Nearest Neighborhood) 등 | |
| sklearn.svm | 서포트 벡터 머신 알고리즘 제공 | |
| sklearn.tree | 의사 결정 트리 알고리즘 제공 | |
| sklearn.cluster | 비지도 클러스터링 알고리즘 제공 (K-평균, 계층형, DBSCAN 등) |
|
| 유틸리티 | sklearn.pipeline | 피처 처리 등의 변환과 ML 알고리즘 학습, 예측 등을 함께 묶어서 실행할 수 있는 유틸리티 제공 |
'AI 머신러닝 딥러닝 > 파이썬 머신러닝 입문 공부일지' 카테고리의 다른 글
| 파이썬 머신러닝 입문 공부일지 13. 교차 검증 (2) Stratified K 클래스 (0) | 2023.01.05 |
|---|---|
| 파이썬 머신러닝 입문 공부일지 12. train_test_split(), 교차 검증 (1) KFold 클래스 (0) | 2023.01.05 |
| 파이썬 머신러닝 입문 공부일지 10. 첫 번째 머신러닝 만들기 - 붓꽃 품종 예측하기 (2) (0) | 2023.01.04 |
| 파이썬 머신러닝 입문 공부일지 9. 사이킷런 기초 시작하기 (사이킷런 설치하기, 첫 번째 머신러닝 만들기 - 붓꽃 품종 예측하기) (1) (0) | 2023.01.04 |
| 파이썬 머신러닝 입문 공부일지 8. apply lambda 데이터 가공 (0) | 2023.01.03 |